Distilling Large Language Models using Skill-Occupation Graph Context
for HR-Related Tasks
Pouya Pezeshkpour
1
Hayate Iso
1
Thom Lake
2
Nikita Bhutani
1
Estevam Hruschka
1
1
Megagon Labs
2
Indeed
{pouya,hayate,nikita,estevam}@megagon.ai [email protected]
Abstract
Numerous HR applications are centered around
resumes and job descriptions. While they can
benefit from advancements in NLP, particularly
large language models, their real-world adop-
tion faces challenges due to absence of com-
prehensive benchmarks for various HR tasks,
and lack of smaller models with competitive
capabilities. In this paper, we aim to bridge
this gap by introducing the Resume-Job De-
scription Benchmark (RJDB). We meticulously
craft this benchmark to cater to a wide array of
HR tasks, including matching and explaining
resumes to job descriptions, extracting skills
and experiences from resumes, and editing re-
sumes. To create this benchmark, we propose
to distill domain-specific knowledge from a
large language model (LLM). We rely on a cu-
rated skill-occupation graph to ensure diversity
and provide context for LLMs generation. Our
benchmark includes over 50 thousand triples
of job descriptions, matched resumes and un-
matched resumes. Using RJDB, we train multi-
ple smaller student models. Our experiments re-
veal that the student models achieve near/better
performance than the teacher model (GPT-4),
affirming the effectiveness of the benchmark.
Additionally, we explore the utility of RJDB on
out-of-distribution data for skill extraction and
resume-job description matching, in zero-shot
and weak supervision manner. We release our
datasets and code
1
to foster further research
and industry applications.
1 Introduction
In organizational recruitment, resumes and job de-
scriptions play a pivotal role, facilitating identifica-
tion of potential candidates and informing hiring
decisions (Zimmermann et al., 2016; Guo et al.,
2021; Ali et al., 2022). Natural Language Process-
ing (NLP) algorithms play a crucial role in enhanc-
ing this process, unraveling valuable information
1
https://github.com/megagonlabs/rjdb
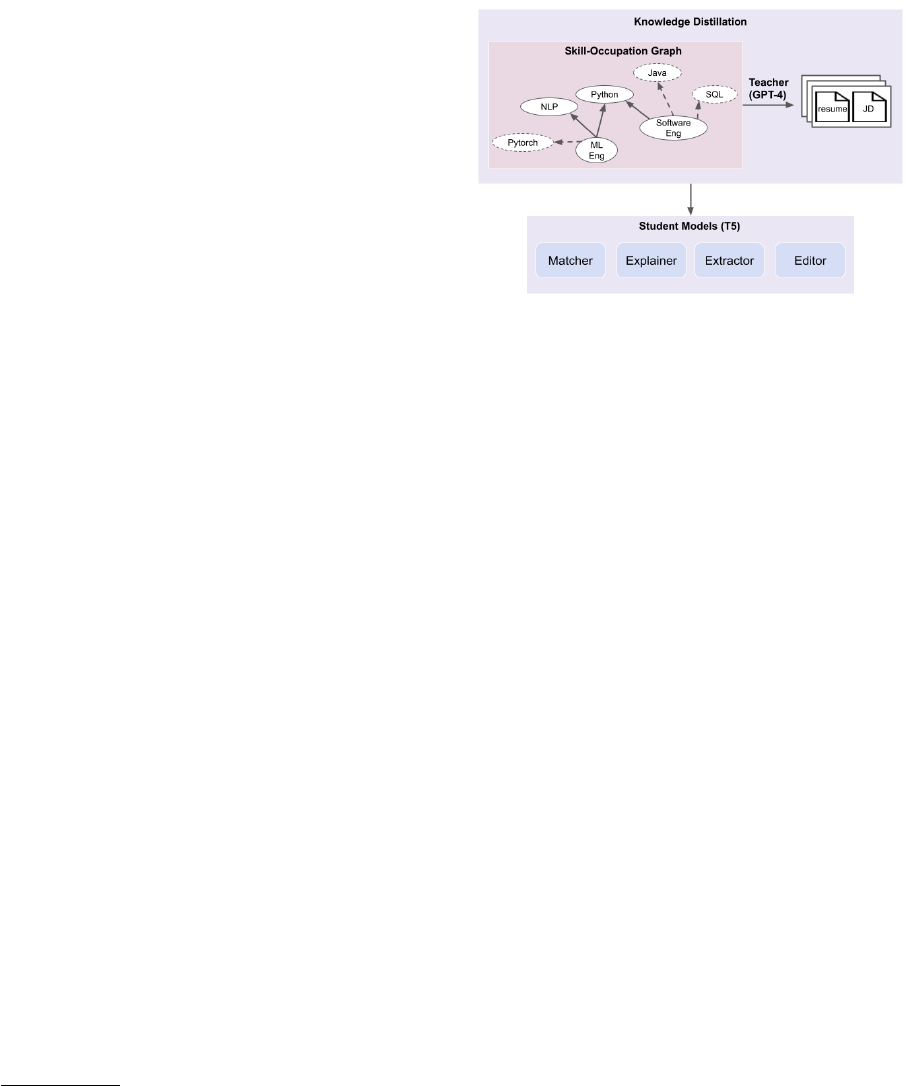
Figure 1: Creating a benchmark for HR-related tasks
via large language model distillation. We start by metic-
ulously sampling subgraphs from our curated skill-
occupation graph. Then, we utilize the skills and occu-
pations contained within these subgraphs as contextual
guidance to steer GPT-4 in the generation of resumes
and job descriptions encompassing a variety of tasks.
and insights embedded within resumes and job de-
scriptions. This include information such as job
titles, skill sets, work history, and educational back-
ground. Leveraging such information can facilitate
a broad variety of HR tasks such as aligning candi-
dates with job openings, streamlining the resume
screening process, and aiding in salary negotiation.
Deploying NLP models for such use cases requires
a diverse and representative dataset covering a wide
range of resumes and job descriptions. However,
there is a noticeable absence of publicly available
large-scale benchmarks tailored for this purpose.
Additionally, many companies heavily rely on pro-
prietary, in-house data to train NLP models. How-
ever, such datasets often carry inherent biases and
noise, and only provide necessary annotation for
limited downstream tasks.
In recent years, several attempts have been made
to create/augment datasets by distilling knowledge
from existing large language models (LLMs) (Kim
et al., 2022; Gu et al., 2023; Li et al., 2023; Gu
arXiv:2311.06383v1 [cs.CL] 10 Nov 2023

et al., 2023). The objective is to extract the knowl-
edge stored in a large teacher model such as GPT-4
(OpenAI, 2023), into a benchmark for a specific
task. Subsequently, this benchmark becomes a valu-
able resource for training smaller student models,
allowing them to emulate the performance of the
teacher model in the targeted task. These student
models present a practical solution for real-world
applications, owing to their reduced size.
Building on the success of prior work in knowl-
edge distillation from LLMs, we propose to dis-
till knowledge from LLMs to generate a multi-
task resume-job description benchmark. As large
language models struggle to generate high qual-
ity and accurate output in low resource domains
(Bang et al., 2023), such as HR, they require to
be provided with necessary guidance as the con-
text (Agrawal et al., 2022; Singhal et al., 2022; Jin
et al., 2023). Skills and past experiences (occu-
pations) are recognized as the foundational infor-
mation required to solve various HR-related tasks
(Qin et al., 2020; Fu et al., 2021; Sun et al., 2021).
Consequently, to guide the knowledge distillation
effort from LLMs, using skill-occupation graph—a
bipartite graph connecting occupations with their
required skills—as the context, emerges as a nat-
ural candidate. Since, to the best of our knowl-
edge, there is no diverse publicly available skill-
occupation graph, we curate our own graph in two
steps: Firstly, we initiate the graph by harvesting
data pertaining to technology-related occupations
and their skills from Dice
2
. Subsequently, we ex-
tend this graph by first extracting general occupa-
tions from the US Bureau of Labor Statistics
3
, and
then leveraging GPT-4 to generate required skills
for these occupations.
Leveraging the structure of the graph, we em-
ploy a sampling process to assemble a diverse set
of interconnected skills and occupations. Then, we
iteratively provide sampled subgraphs as context to
GPT-4 to generate more than 50,000 triples, each
comprising a job description, a matched resume,
and an unmatched resume. We craft the genera-
tion pipeline such that it yields triples that serve
as resources for training and evaluating models
across several pivotal tasks: (1) Job-Candidate
Matching: Assessing the compatibility between
job openings and potential candidates. (2) Coun-
2
https://www.dice.com
. We extracted the data from
https://www.kaggle.com/datasets/PromptCloudHQ/
us-technology-jobs-on-dicecom
3
https://www.bls.gov/oes/current/oes_stru.htm
terfactual Explanation for Matching: Exploring
explanations and reasoning behind job-candidate
matches. (3) Information Extraction: Extracting
pertinent details, such as skills and occupations,
from both resumes and job descriptions. And, (4)
Resume Editing: Facilitating the enhancement
and refinement of resumes for candidates. We pro-
vide an overview of our pipeline to generate RJDB
in Figure 1.
After creating the resume-job description bench-
mark (RJDB), we train individual student mod-
els based on Flan-T5 base (Chung et al., 2022)
for each specific task within the dataset. Our stu-
dent models demonstrate comparable/superior per-
formance across different tasks, when compared
against the GPT-4 teacher model over held-out data
from the benchmark. To explore the broader utility
of RJDB, we extend our investigation to include
out-of-distribution data, specifically focusing on
two tasks: resume-job matching and skill extrac-
tion. Remarkably, our student models, fine-tuned
on RJDB, excel in these tasks. We also find that the
models fine-tuned on out-of-distribution data when
further fine-tuned using RJDB, yield enhanced per-
formance and improved generalization.
Contributions The main contributions of this pa-
per are as follows: (1) We create a multi-task
resume-job description benchmark (RJDB) to over-
come existing datasets limitations in the HR do-
main. (2) We curated a diverse skill-occupation
graph and utilized it as the context guiding our
benchmark generation process. (3) We intro-
duced a novel distillation pipeline for HR; our ap-
proach comprises various innovative components
that leverage domain-specific expertise and harness
the world-knowledge from GPT-4 to effectively
address numerous existing challenges in the HR
domain. (4) Training multiple student models us-
ing RJDB on the proposed tasks, we release strong
baselines that achieved performance on par with or
surpassing the teacher model (GPT-4). Finally, (5)
we explored potential use cases of RJDB in out-of-
distribution data. We have made our data, models,
and code publicly available, aiming to facilitate and
advance progress within the HR domain.
2 Distilling LLMs For HR-Related Tasks
To generate high-quality documents in HR domain,
it is crucial to provide knowledge intensive con-
text to guide large language models. Furthermore,
since our goal is to generate documents satisfy-

ing multiple HR-related downstream tasks, this
context should contain necessary annotations for
these tasks. As a result, subgraphs from a skill-
occupation graph naturally emerge as a suitable
candidate to serve as context for guiding LLM gen-
eration. Leveraging a skill-occupation graph to dis-
till knowledge from LLMs presents us with three
distinct challenges: (1) The scarcity of publicly
available skill-occupation graphs that cover a wide
range of general occupations. (2) The need to sam-
ple subgraphs that not only provide the necessary
guidance for LLMs but also yield documents that
align with real-world distributions. And, (3) the
requirement to generate documents that are both
diverse and faithful to the provided context while
offering essential annotations for downstream tasks.
In this section, we take on these challenges by first
curating our skill-occupation graph and then in-
troducing our generation pipeline to construct our
multi-task benchmark. Following the introduction
of our pipeline, we then proceed to conduct a com-
prehensive quality assessment of the generated doc-
uments.
2.1 Skill-Occupation Graph
The skill-occupation graph (Dave et al., 2018;
de Groot et al., 2021; Boškoski et al., 2022) is
a powerful tool in the realm of workforce develop-
ment and career matching, defined as a bipartite
graph that links occupations with their required
skills. Our objective is to extract subsets from this
graph to guide the generation of resumes and job
descriptions. To the best of our knowledge, the
only publicly accessible skill-occupation graph is
sourced from DICE which only covers technology
related occupations. As a result, to generate diverse
resumes and job descriptions, we need to construct
our own graph encompassing a broader variety of
occupational categories. Beyond data availability,
the most significant challenge in developing such
a graph is ensuring its representation aligns with
real-world distribution. Thus, in this section, as
a proactive step in overcoming these challenges,
we start constructing our graph with a foundation
in technology-related graph from DICE. Building
upon this foundation, we extend the graph by ex-
tracting general occupations from the US Bureau of
Labor Statistics. We then generate required skills
for each one of those occupations by prompting
GPT-4.
#Occ #Skill #Edges
#Avg Skill #Avg Occ
per Occ per Skill
8275 14807 70661 8.5 4.8
Table 1: Data statistics of the curated skill-occupation
graph.
Generating Skills for General Occupations To
diversify our graph beyond technology-related oc-
cupations, we incorporate 1,112 diverse occupa-
tions sourced from the US Bureau of Labor Statis-
tics. The process of generating the required skills
for these occupations involves several steps. Ini-
tially, we match each occupation with the clos-
est counterpart in our in-house proprietary skill-
occupation graph, leveraging Phrase-BERT (Wang
et al., 2021). Subsequently, we extract the number
of provided skills associated with the matched oc-
cupation from the graph. This process is vital for
ensuring that distribution of skills in the generated
graph aligns with real-world distribution. For each
occupation and its respective extracted number of
skills, denoted as
n
, we employ GPT-4 to gener-
ate required skills for the occupation by using the
prompt:
Prompt 2.1: Prompt for skill generation
Generate {n} number of required skills necessary
for the occupation {OCCUPATION}.
Filtering the Curated Graph In order to sample
diverse subgraphs from our curated graph while
effectively filtering out rare skills and occupations,
we employ a clustering strategy. We adopt density-
based clustering and initiate the process by select-
ing a random occupation as a seed, then gradually
expand the cluster to encompass any node within
a two-hop radius. This expansion continues itera-
tively until all occupations are included within a
cluster. Subsequently, we eliminate clusters that
contain fewer than 10 occupational nodes. As a
result of this process, we successfully partition and
filter the graph into 404 distinct clusters, with an
average of approximately 84.2 occupational nodes
within each cluster. A statistical overview of the
resulting graph is presented in Table 1.
2.2 Generation Pipeline
In the process of generating resumes and job de-
scriptions, our approach involves sampling sub-
graphs from the curated skill-occupation graph to
serve as context for LLMs. These subgraphs com-

prise sets of skills and past experiences (occupa-
tions) that are to be integrated into a candidate’s
resume and a job description. To ensure the quality
and authenticity of generated documents, several
necessary requirements must be met. Firstly, the
number of sampled skills and experiences should
align with the real-world distribution of these com-
ponents within a resume or job description. Fur-
thermore, the provided experiences should main-
tain a logical chronological order and incorporate
temporal information. Beyond these prerequisites,
we aim to create unbiased and diverse documents
while simultaneously providing essential annota-
tions for downstream tasks. In this section, we
shape our document generation pipeline to adhere
to these requirements. Given the absence of read-
ily available data to help addressing these require-
ments, we mostly rely on the world knowledge
embedded in GPT-4 to fulfill them.
Subgraph Sampling To initiate the subgraph
sampling process, we begin by randomly select-
ing a cluster and an occupational node within that
cluster as our starting node. To sample a subgraph,
we implement random walks from the starting node
and configure the random walks parameters to en-
sure that the expected number of sampled skills
and experiences (occupations) align with prede-
fined values. To specify the predefined number of
experiences, in each sampling step, we randomly
select a value ranging from 1 to 5. For the prede-
fined number of skills, we turn to GPT-4 and pose
the question:
Prompt 2.2: Prompt for subgraph sampling
On average how many skills does a person with a
job title of ‘{Starting Node}’ may have listed
in his or her resume?
This approach enables us to align the number of
skills in generated documents with the real-world
distribution, accomplished by using GPT-4’s exten-
sive world knowledge, tailored to a specific occu-
pation.
Chronological Order of Experiences in a Sam-
pled subgraph After sampling a subgraph, the
past experiences are presented in a random se-
quence. However, in actual real-world resumes,
past experiences typically follow a logical chrono-
logical order, reflecting an applicant’s career pro-
gression over time. For instance, an applicant com-
monly starts as a Software Engineer before advanc-
ing to the role of a Senior Software Engineer. To
rectify this, we turn to GPT-4’s world knowledge
by prompting it with the prompt:
Prompt 2.3: Prompt for ordering experiences
Given the previous experiences of individuals
with {list of Past Experiences}, please arrange
them in a chronological order based on the
likelihood of encountering these experiences
from earlier to later over time.
This aids us in establishing the correct chrono-
logical order for the sampled past experiences.
Incorporating Temporal Information into Ex-
periences We exclusively attribute temporal data
to the past experiences within resumes and job de-
scriptions. To accomplish this, we follow a process
in which we randomly select a value between 1 and
5, signifying the number of years a particular expe-
rience spans. However, when generating resumes,
rather than specifying years of involvement, we
introduce a different approach. By selecting a ran-
dom year between 2015 and 2023 (representing the
last year of being active), we gradually reduce the
number of years attributed to each experience. This
method allows us to establish a specific time frame
for each past experience, for instance, spanning
from 2017 to 2021.
Diversifying Resumes based on Gender and
Race In our pursuit of generating diverse re-
sumes with respect to race and gender, we concen-
trate on the applicant’s first name. Our approach
involves extracting a list of the most popular given
names that are uniformly distributed across various
racial categories, sourced from Wikipedia
4
. This
results in a collection of approximately 700 first
names, separately for both males and females. In
each generation step, we prioritize maintaining a
balanced distribution of male and female names
across various occupation types, ensuring that ev-
ery cluster comprises an equal number of generated
resumes for both genders. Additionally, as these
first names are uniformly distributed across differ-
ent racial groups, uniformly sampling them further
ensures the race diversity of generated resumes.
Task Specific Annotation As our objective is to
construct a benchmark capable of encompassing
multiple tasks, we must ensure that our genera-
tion process aligns with the distinct requirements
4
https://en.wikipedia.org/wiki/List_of_most_
popular_given_names

Figure 2: Evaluating the quality of generated documents using various approaches with G-eval.
of each task. Given that our approach generates
both resumes and job descriptions from the same
initial set of skills and experiences, the prerequi-
sites for both the matching and extracting tasks
are inherently fulfilled. To facilitate the necessary
annotations for resume editing and matching ex-
planation, alongside generating a job description
and a matched resume, we introduce an unmatched
resume by deliberately altering certain elements
within the matched resume. Specifically, we ran-
domly remove between 1 to 5 skills and decrease
the duration of engagement in the last experience
by randomly selecting a number equal to or less
than the original years of involvement.
2.3 Quality Assessment
With our generation pipeline outlined, our next step
involves determining whether we can leverage In-
structGPT (text-davinci-003) (Ouyang et al., 2022)
or if a more advanced model like GPT-4 (OpenAI,
2023) is required for resume-job description distil-
lation. Additionally, we aim to ascertain whether
it’s more advantageous to generate documents sec-
tion by section or produce the entire document in
one go. To address these inquiries, we delve into
the evaluation of consistency and factuality in the
generated documents, employing G-eval (Liu et al.,
2023), an evaluation method based on large lan-
guage models. Also, we conduct a human study
to gain a deeper understanding of the quality of
generated documents.
LLM-based Evaluation We employ G-eval to
conduct automated assessments of the consistency
and factuality of the generated documents, to ex-
plore the impact of different LLMs and generation
methods (section by section or in its entirety). G-
eval evaluation only requires the input document,
along with criteria and chain-of-thought style (Wei
et al., 2022) instructions for scoring the document
on a scale of 1 to 5 (detailed prompts are avail-
able in Appendix). The outcomes of our evaluation
are presented in Figure 2. The results indicate
that, in general, GPT-4’s approach of generating
Factulity Consistency
Dice 63.4 62.7
Generated 67.9 65.4
Table 2: User study on the quality of generated job-
descriptions.
the entire document at once demonstrates superior
performance across both criteria. As a result, we
consider this approach as the primary component
in our generation pipeline in the remainder of this
paper.
Human-based Evaluation We further assess the
quality of generated documents through a user
study. Since resumes can contain sensitive data,
we only focus on the quality of generated job de-
scriptions and compare it to real job descriptions
gathered from Dice
5
. We evaluate the quality of
generated versus real world job description through
two criteria: (1) Realisticness, measuring how
probable is the provided job description to be a
human written job description for an actual job. (2)
Consistency, measuring how well the various el-
ements within the job description, including job
title, skills, and requirements, align with one an-
other. We consider 100 generated job descriptions
and extract 100 most similar job descriptions from
Dice using phrase-BERT (Wang et al., 2021) on
job titles. We provide each sample to 3 annotators
asking them to score the document based on both
criteria on as scale from 1-100. Then, we calculate
the average score for each sample.
The outcomes of the user study are presented in
Table 2. The results indicate that the generated job
descriptions exhibit a higher degree of realisticness
and consistency compared to real job descriptions.
One possible explanation for the higher scores of
generated job descriptions could be attributed to
the fact that we consistently generate fixed sections
for all job descriptions, whereas many of the Dice
job descriptions lack well-defined sections.
5
https://www.dice.com

#Doc Avg #W Min #W Max #W
JD 52K 181.1 70 427
R-M 52K 101.9 30 604
R-U 52K 87.1 23 395
Table 3: Data statistics of RJDB. We report the num-
ber of generated documents (#Doc), and also average,
minimum, and maximum number of words (#W) for
job descriptions (JD), matched resumes (R-M), and un-
matched resumes (R-U).
Avg #Skills Avg #Exp
Sampled 6.43 2.44
Removed 1.9 -
Table 4: The average number of skills and past experi-
ences in each triple, as well as the average number of
skills removed to generate the unmatched resume from
the matched one.
3 Resume-Job Description Benchmark
(RJDB)
Incorporating our generation pipeline, our goal was
to create the Resume-Job Description Benchmark
(RJDB), which comprises 52,000 triples of job de-
scriptions, matched resumes, and unmatched re-
sumes. Details regarding the prompt used for gen-
erating these triples can be found in Appendix. For
insights into the data statistics, including the num-
ber of tokens in the generated documents, please
refer to Tables 3. Additionally, Tables 4 present
the average number of sampled skills, experiences,
and the average number of removed skills to create
the unmatched resume from the matched ones.
To delve deeper into the distribution of the gen-
erated documents, we categorized them into five
distinct groups: (1) tech, (2) social, product, and
finance, (3) manual labor, (4) healthcare, and (5)
administrative. The distribution of triples across
these categories is depicted in Figure 3. Further-
more, a more detailed breakdown of the average
number of skills, and words in each document can
be found in Figure 4. Remarkably, documents re-
lated to the tech industry exhibit a lower average
number of skills and words. This phenomenon may
be attributed to the distinctive graph structure sur-
rounding tech-related occupations, as well as the
diversity of these occupations in the graph covering
different level of expertise.
4 Student Models
Now that we have successfully generated the RJDB,
the next crucial step involves the training of FLAN-
Figure 3: Distribution of different job categories over
generated documents.
T5 base student models (which we refer to as T5
in the remainder of paper). This includes train-
ing T5 on matching, explaining, extracting, and
editing tasks. Upon fine-tuning T5 on these tasks
we compare it against our teacher model, GPT-4.
This comparative analysis is essential to measure
the capabilities and potential of student models in
capturing knowledge of teacher model. To achieve
this, we divide the RJDB to train, test, and dev set
with the size of 50000, 1000, and 1000 samples
respectively.
Matcher and Explainer We fine-tune the T5
student model for both matching and explaining
tasks simultaneously. When presented with pairs
of resumes and job descriptions, our goal here is
not only to predict their compatibility but also to
explain the reasons behind this determination by
providing a set of matching or mismatching skills
and experiences. For negative pairs, we consider
modifications on the matched resume, to create the
un-matched version, to be the explanation, while
for positive examples we consider the set of seed
skills and experiences as the explanation. Con-
sidering the complicated nature of evaluating ex-
planations, here, we only report the percentage
of modifications that appear in the explanations
in negative pairs, to evaluate the explaining capa-
bility of models. The results for matching and
explaining capability of models are presented in
Table 5. Remarkably, the student model exhibit an
outstanding level of performance, outperforming
GPT-4 (teacher) in both tasks. Based on T5 perfor-
mance, it seems that if provided with a big enough
benchmark a smaller model can achieve compara-

(a) Distribution of average number of
skills.
(b) Distribution of average number of
words per resume.
(c) Distribution of average number of
words per job description.
Figure 4: Distribution of number of skills and words in generated documents.
ble performance with a much larger teacher model
on matching and explaining tasks when tested over
the data from the same distribution as training data.
Extractor We also fine-tune a student model
to extract skills and past experiences from re-
sumes and job descriptions. The results of our stu-
dent models performances are presented in Table
6. Both models generally exhibit superior perfor-
mance when extracting information from resumes
compared to job descriptions. This observation
may be attributed to the typically shorter length of
resumes, and possibly more explicit appearance of
information in resumes compared to job descrip-
tions. Furthermore, in the extraction of past expe-
riences, student models consistently either outper-
form or perform at a comparable level to the teacher
model in both resume and job descriptions. Con-
versely, in the task of skill extraction, while student
models exhibit similar average F1 performance, a
noticeable disparity in accuracy becomes apparent
between the teacher and the student model. Sug-
gesting that this task may demand a higher level of
reasoning, which emphasizes the potential need for
a larger student model or a more complex training
procedure.
Editor Our final student model is tailored for the
resume editing task, focusing on the reconstruc-
tion of the skills and experiences section within the
unmatched resume to create the matched version.
We use the entirety of the unmatched resume as an
input and incorporating the modifications made to
the matched resume to create the unmatched coun-
terpart as an extra signal, which includes the skills
that were removed and changes to the last experi-
ence. In evaluating the model’s performance, in
addition to ROUGE2 score (Lin, 2004), we employ
F
add
(Xu et al., 2016), measuring F1 score by re-
warding the n-grams (bi-grams in our setting) that
Models
Matching Explaining
Acc F1 Acc
GPT-4 83.2 82.8 37.8
T5 93.1 93.1 53.7
Table 5: Performance of the teacher and student models
on matching and explaining tasks.
Models
Skill Experience
Acc F1 Acc F1
Res
GPT-4 79.2 81.9 56.6 57.7
T5 60.8 73.9 55.5 64.5
JD
GPT-4 83.9 77.1 41.5 40.1
T5 60.5 73.6 53.3 63.1
Table 6: Performance of the teacher and student models
on information extraction task.
appear in the model output and the reference docu-
ment (extra signals) but did not appear in the input
document (unmatched resume). The outcomes of
models’ performance are provided in Table 7. Both
models show higher level of performance when
editing experience section. Additionally, T5 excels
in the
F
add
metric while underperforming in the
ROUGE metric comparing to GPT-4, highlighting
the observation that student models tend to produce
more concise and precise contents.
5 Out-of-Distribution Use Cases
To explore the broader applications of RJDB, we
delve into scenarios focusing on out-of-distribution
cases. This encompasses two key aspects: zero-
shot adoption, where we apply our models fine-
tuned on RJDB to outside data, and weak supervi-
sion, which involves using our dataset to further
fine-tune models trained on out-of-distribution data.
Since, the resume editing and explanation tasks re-
main relatively under-explored, and finding avail-
able resources for them proved to be a challenge,

Models ROUGE F
add
Skill
GPT-4 0.347 0.262
T5 0.278 0.271
Exp
GPT-4 0.391 0.374
T5 0.328 0.513
Table 7: Performance of the teacher and student models
on resume editing task.
here, we only focus on matching and extraction
tasks. For matching, we utilize the Machop dataset
created by Wang et al. (2022) from Indeed data,
containing 2000 resume and job-description pairs
divided into 1200, 400, 400 samples as train, test,
and dev set respectively. Additionally, we use 688
resumes and their annotated skills provided in Ma-
chop for skill extraction task.
Zero-Shot Adaptation in Matching For adopt-
ing our student model to be able to zero-shot pre-
dicting out-of-distribution data, in matching task,
we need to incorporate noise into the data they
are trained on. To do so, we consider un-matched
generated resumes with maximum changes as posi-
tive samples. Also, we sample some random pairs
of resume-job description for negative samples,
creating a training set with around 12000 sam-
ples. As matching baselines, we consider Machop-
Sequence (Wang et al., 2022) and Ditto (Li et al.,
2020) which are both language model based solu-
tions. The zero-shot performance of our student
model is provided in Table 8 (T5-R (Zero-shot)).
Despite the fact that our T5-R (Zero-shot) was not
trained on Machop data, surprisingly, not only it
performs similarly to previously reported state-of-
the-art model (Machop-S), it achieves higher per-
formance in precision.
Weak Supervision in Matching HR-related
tasks are highly dependent on social and economic
conditions. For example, in an economic scenario
where job applicants outnumber available positions,
it may be necessary to implement a matching model
that, while potentially sacrificing some true posi-
tive applicants for a job description, significantly
reduces false positive cases. As a result, a contin-
uous model adaptation becomes essential in order
to address these ever-changing dynamics. RJDB
can provide us with a controllable resource for tai-
loring existing models in a weak supervise manner
to meet the requirements dictated by social and
economic conditions. Fine-tuning a base Flan-T5
model on Machop dataset (Wang et al., 2022) -
F1 Rec Prec
In
Ditto 66.4 81.7 56.0
Machop-S 83.5 90.8 77.3
T5-M 46.7 65.8 36.2
Out
T5-R (Zero-shot) 80.5 77.5 83.8
T5-M+R (Weak-Rec) 45.4 83.3 31.2
T5-M+R (Weak-Pre) 50.0 56.7 44.4
Table 8: Matching task performances on out-of-
distribution data.
Models
Test-Machop Human
Acc F1 Rec Prec Acc Avg #
T5-M 84.5 90.0 89.6 90.9 43.3 0.18
T5-R 65.5 52.0 48.1 61.9 78.6 1.95
T5-M+R 83.1 88.1 87.7 89.3 55.0 0.35
Table 9: Skill extraction task on out-of-distribution.
dataset (T5-M), the goal here is to explore the po-
tential of utilizing RJDB data to further enhance
this model. Considering the small training size
of Machop dataset (1200 samples), fine-tuned T5
performs very poorly (Table 8). We explore two
scenarios: (1) one aimed at enhancing recall and
(2) the other focused on improving precision. In the
first scenario, we perform minimal additional fine-
tuning on T5-M using a randomly selected subset
of the created training set in previous part (which
consists of 12,000 samples) containing 1,000 ran-
dom samples, referred to as T5-M+R (Weak-Rec).
In the second scenario, we randomly select 500
pairs of positive and negative resume-job descrip-
tion combinations from RJDB to further fine-tune
T5-M (referred to as T5-M+R (Weak-Pre)). The
results are presented in Table 8. As the table illus-
trates, by leveraging RJDB, we can enhance recall
and precision of T5-M by approximately 17.8%
and 8.2%, respectively, with only marginal posi-
tive/negative effects on other metrics.
Skill Extraction in Out-of-Distribution Data
For skill extraction, we explore the effects of fine-
tuning student models using RJDB on enhancing
their generalization capabilities. To achieve this we
adopt resumes provided in Machop, which are ac-
companied with their annotated skills from Indeed.
We randomly select 100 resumes as the test set, 88
samples as dev set, and designate the remaining
500 resumes as the training set. We fine-tune a T5
model using three different datasets: (1) solely the
Machop training set (T5-M), (2) solely a random
sample of 1000 resumes from RJDB (T5-R), we
choose a small set to be comparable to Machop
training set, and (3) a combination of the Machop
data and sampled resumes from RJDB (T5-M+R).
The results of these models’ performance on the
Machop test set are presented in Table 9. Further-
more, to assess the generalization capabilities of
these models, we manually verify the accuracy of
additional skills extracted, i.e., predicted skills be-
yond the labeled ones, by each model from the test
set resumes. The accuracy and average number of
extra skills for each model are presented in Table 9
(Human assessment). As demonstrated, T5-M+R
can extract a significantly larger number of new
skills with only a minor sacrifice in performance
compared to T5-M. Similarly, while T5-R may un-
derperform when compared to other models on the
Machop test set, it successfully extracts a larger
number of new skills with a higher accuracy.
6 Related Work
Language models can be an invaluable asset for
HR-related tasks, but their widespread adoption in
real-world applications is hindered by the absence
of publicly available multi-task datasets.
NLP for HR In recent years, the integration
of language models into human resources-related
tasks has witnessed a notable surge in interest
and innovation. These advanced natural language
processing models have shown great promise in
addressing the intricacies of HR tasks, ranging
from resume parsing and job description match-
ing to skill extraction and beyond. Bian et al.
(2020) proposed a multi-view co-teaching network
for job-resume matching, designed to effectively
leverage sparse and noisy interactions available be-
tween candidates and jobs. Mahdi et al. (2021);
Li et al. (2021) introduced a BERT based (Devlin
et al., 2019) information extraction from job de-
scriptions and resumes respectively. Authors in
Fang et al. (2023) proposed a skill-aware prompt
learning module to improve the pre-trained model’s
adaptability to downstream HR-related tasks.
Knowledge Distillation from LLMs Knowl-
edge Distillation is a technique used for reduc-
ing the high computational demand of LLMs by
transferring knowledge from a large teacher model
to a smaller student one (Gu et al., 2023). Kim
et al. (2022) curated a million-scale social dia-
logue dataset by distilling knowledge from Instruct-
GPT. West et al. (2021) extracted commonsense
symbolic knowledge from large language models,
while Li et al. (2023) introduced the distillation of
chain-of-thought-style reasoning from LLMs to en-
hance the reasoning capabilities of smaller models.
7 Conclusion
We introduce the Resume-Job Description Bench-
mark (RJDB) by distilling knowledge from GPT-
4. Starting from subgraphs sampled from our cu-
rated skill-occupation graph, we generate resume
and job description catering to multiple HR-related
tasks, from matching and explanation to skill and
experience extraction. We generate 52,000 triples
of job descriptions, matched and unmatched re-
sumes and successfully train student models that
rival or surpass the teacher model (GPT-4) on in-
distribution data. Moreover, we extend our inves-
tigation to demonstrate the adaptability of RJDB
in handling out-of-distribution data for skill extrac-
tion and resume-job description matching, using
zero-shot and weak supervision techniques. We
believe RJDB lays a strong foundation for HR-
related tasks, fostering the development of models
and techniques that can bridge the gap between
research and real-world applications in the field of
HR.
References
Monica Agrawal, Stefan Hegselmann, Hunter Lang,
Yoon Kim, and David Sontag. 2022. Large language
models are few-shot clinical information extractors.
In Proceedings of the 2022 Conference on Empiri-
cal Methods in Natural Language Processing, pages
1998–2022.
Irfan Ali, Nimra Mughal, Zahid Hussain Khand, Javed
Ahmed, and Ghulam Mujtaba. 2022. Resume clas-
sification system using natural language processing
and machine learning techniques. Mehran Univer-
sity Research Journal Of Engineering & Technology,
41(1):65–79.
Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wen-
liang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei
Ji, Tiezheng Yu, Willy Chung, et al. 2023. A multi-
task, multilingual, multimodal evaluation of chatgpt
on reasoning, hallucination, and interactivity. arXiv
preprint arXiv:2302.04023.
Shuqing Bian, Xu Chen, Wayne Xin Zhao, Kun Zhou,
Yupeng Hou, Yang Song, Tao Zhang, and Ji-Rong
Wen. 2020. Learning to match jobs with resumes
from sparse interaction data using multi-view co-
teaching network. In Proceedings of the 29th ACM
International Conference on Information & Knowl-
edge Management, pages 65–74.
Pavle Boškoski, Matija Perne, Tjaša Redek, and Bil-
jana Mileva Boshkoska. 2022. Occupation sim-
ilarity through bipartite graphs. arXiv preprint
arXiv:2202.11064.
Hyung Won Chung, Le Hou, Shayne Longpre, Bar-
ret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi
Wang, Mostafa Dehghani, Siddhartha Brahma, et al.
2022. Scaling instruction-finetuned language models.
arXiv preprint arXiv:2210.11416.
Vachik S Dave, Baichuan Zhang, Mohammad Al Hasan,
Khalifeh AlJadda, and Mohammed Korayem. 2018.
A combined representation learning approach for bet-
ter job and skill recommendation. In Proceedings of
the 27th ACM International Conference on Informa-
tion and Knowledge Management, pages 1997–2005.
Maurits de Groot, Jelle Schutte, and David Graus. 2021.
Job posting-enriched knowledge graph for skills-
based matching. arXiv preprint arXiv:2109.02554.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2019. Bert: Pre-training of deep
bidirectional transformers for language understand-
ing. In Proceedings of the 2019 Conference of the
North American Chapter of the Association for Com-
putational Linguistics: Human Language Technolo-
gies, Volume 1 (Long and Short Papers), pages 4171–
4186.
Chuyu Fang, Chuan Qin, Qi Zhang, Kaichun Yao, Jing-
shuai Zhang, Hengshu Zhu, Fuzhen Zhuang, and
Hui Xiong. 2023. Recruitpro: A pretrained language
model with skill-aware prompt learning for intelli-
gent recruitment. In Proceedings of the 29th ACM
SIGKDD Conference on Knowledge Discovery and
Data Mining, pages 3991–4002.
Yan Fu, Nan Li, Juan Feng, and Qiang Ye. 2021. In-
congruent skills and experiences in online labor mar-
ket. Electronic Commerce Research and Applica-
tions, 45:101025.
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang.
2023. Knowledge distillation of large language mod-
els. arXiv preprint arXiv:2306.08543.
Feng Guo, Christopher M Gallagher, Tianjun Sun, Saba
Tavoosi, and Hanyi Min. 2021. Smarter people ana-
lytics with organizational text data: Demonstrations
using classic and advanced nlp models. Human Re-
source Management Journal.
Qiao Jin, Yifan Yang, Qingyu Chen, and Zhiyong Lu.
2023. Genegpt: Augmenting large language models
with domain tools for improved access to biomedical
information. ArXiv.
Hyunwoo Kim, Jack Hessel, Liwei Jiang, Ximing Lu,
Youngjae Yu, Pei Zhou, Ronan Le Bras, Malihe
Alikhani, Gunhee Kim, Maarten Sap, et al. 2022.
Soda: Million-scale dialogue distillation with so-
cial commonsense contextualization. arXiv preprint
arXiv:2212.10465.
Liunian Harold Li, Jack Hessel, Youngjae Yu, Xi-
ang Ren, Kai-Wei Chang, and Yejin Choi. 2023.
Symbolic chain-of-thought distillation: Small mod-
els can also" think" step-by-step. arXiv preprint
arXiv:2306.14050.
XiaoWei Li, Hui Shu, Yi Zhai, and ZhiQiang Lin. 2021.
A method for resume information extraction using
bert-bilstm-crf. In 2021 IEEE 21st International
Conference on Communication Technology (ICCT),
pages 1437–1442. IEEE.
Yuliang Li, Jinfeng Li, Yoshihiko Suhara, AnHai Doan,
and Wang-Chiew Tan. 2020. Deep entity matching
with pre-trained language models. arXiv preprint
arXiv:2004.00584.
Chin-Yew Lin. 2004. Rouge: A package for automatic
evaluation of summaries. In Text summarization
branches out, pages 74–81.
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang,
Ruochen Xu, and Chenguang Zhu. 2023. Gpteval:
Nlg evaluation using gpt-4 with better human align-
ment. arXiv preprint arXiv:2303.16634.
Hussain Falih Mahdi, Rishit Dagli, Ali Mustufa, and
Sameer Nanivadekar. 2021. Job descriptions key-
word extraction using attention based deep learning
models with bert. In 2021 3rd International Congress
on Human-Computer Interaction, Optimization and
Robotic Applications (HORA), pages 1–6. IEEE.
OpenAI. 2023. Gpt-4 technical report. arXiv preprint
arXiv:2303.08774.
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car-
roll L Wainwright, Pamela Mishkin, Chong Zhang,
Sandhini Agarwal, Katarina Slama, Alex Ray, et al.
2022. Training language models to follow in-
structions with human feedback. arXiv preprint
arXiv:2203.02155.
Chuan Qin, Hengshu Zhu, Tong Xu, Chen Zhu, Chao
Ma, Enhong Chen, and Hui Xiong. 2020. An en-
hanced neural network approach to person-job fit in
talent recruitment. ACM Transactions on Informa-
tion Systems (TOIS), 38(2):1–33.
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mah-
davi, Jason Wei, Hyung Won Chung, Nathan Scales,
Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl,
et al. 2022. Large language models encode clinical
knowledge. arXiv preprint arXiv:2212.13138.
Ying Sun, Fuzhen Zhuang, Hengshu Zhu, Qi Zhang,
Qing He, and Hui Xiong. 2021. Market-oriented job
skill valuation with cooperative composition neural
network. Nature communications, 12(1):1992.
Jin Wang, Yuliang Li, Wataru Hirota, and Eser Kan-
dogan. 2022. Machop: An end-to-end generalized
entity matching framework. In Proceedings of the
Fifth International Workshop on Exploiting Artificial
Intelligence Techniques for Data Management, pages
1–10.
Shufan Wang, Laure Thompson, and Mohit Iyyer. 2021.
Phrase-bert: Improved phrase embeddings from bert
with an application to corpus exploration. arXiv
preprint arXiv:2109.06304.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten
Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou,
et al. 2022. Chain-of-thought prompting elicits rea-
soning in large language models. Advances in Neural
Information Processing Systems, 35:24824–24837.
Peter West, Chandra Bhagavatula, Jack Hessel, Jena D
Hwang, Liwei Jiang, Ronan Le Bras, Ximing
Lu, Sean Welleck, and Yejin Choi. 2021. Sym-
bolic knowledge distillation: from general language
models to commonsense models. arXiv preprint
arXiv:2110.07178.
Wei Xu, Courtney Napoles, Ellie Pavlick, Quanze Chen,
and Chris Callison-Burch. 2016. Optimizing sta-
tistical machine translation for text simplification.
Transactions of the Association for Computational
Linguistics, 4:401–415.
Tim Zimmermann, Leo Kotschenreuther, and Karsten
Schmidt. 2016. Data-driven hr-r
\
’esum
\
’e analysis
based on natural language processing and machine
learning. arXiv preprint arXiv:1606.05611.
A Details of Prompts
We present the prompts utilized in G-eval for as-
sessing consistency and factuality in Figures 5 and
6, respectively. Additionally, the prompt used in
our generation pipeline for generating triples of
job descriptions, matched resumes, and unmatched
resumes is provided in Figure 7.

Consistency
# Instruction:
As a hiring manager, your task is to evaluate job descriptions on a scale of 1-5. This scale represents the consistency of
the job description, with 1 being completely inconsistent and 5 being fully consistent. Your evaluation should consider
the alignment of job responsibilities, required skills, qualifications, and the overall tone of the job description,
as well as the consistency between different sections of the job description. Please ensure you fully understand these
instructions before proceeding.
# Evaluation Criteria:
1. Completely Inconsistent: The job responsibilities, required skills, qualifications, and overall tone of the job
description are not aligned. The description is confusing and does not provide a clear understanding of the job.
Additionally, there are significant inconsistencies between different sections of the job description, making it
confusing and unclear.
2. Mostly Inconsistent: There are some elements of the job description that align, but there are significant
inconsistencies between different sections that make the description unclear.
3. Somewhat Consistent: The job description has a fair amount of alignment between the responsibilities, skills, and
qualifications, as well as between different sections, but there are areas that could be improved for clarity.
4. Mostly Consistent: The job description is mostly aligned, both within sections and between different sections, with
only minor inconsistencies. The description provides a clear understanding of the job.
5. Fully Consistent: The job responsibilities, required skills, qualifications, and overall tone of the job description
are perfectly aligned. Additionally, there is a high level of consistency between different sections, resulting in
a clear and comprehensive understanding of the job.
# Evaluation Steps:
1. Carefully read the entire job description, focusing on the alignment between the job responsibilities, required
skills, qualifications, and the overall tone of the description.
2. Evaluate the overall consistency of the job description based on the provided criteria.
3. Assign a consistency score ranging from 1 to 5, using the Evaluation Criteria as a guide.
# Required Skills:
{skills}
# Required Experience:
{experience}
# Job Description:
{job description}
# Evaluation Form (scores ONLY):
Figure 5: The prompt used for assessing the consistency in generated job descriptions. We use the same prompt,
changing job descriptions to resumes, for resumes as well.

Factuality
# Instruction:
As a hiring manager, your task is to evaluate job descriptions on a scale of 1-5. This scale represents the factuality
of the job description, with 1 being completely false and 5 being completely true. Your evaluation should consider the
accuracy of the job responsibilities, required skills, qualifications, and the overall representation of the job role.
Please ensure you fully understand these instructions before proceeding.
# Evaluation Criteria:
1. Completely False: The job description does not match the job title at all. The responsibilities, required skills,
and qualifications are misleading or incorrect.
2. Mostly False: The job description has some elements of truth but contains significant inaccuracies or exaggerations
in the responsibilities, required skills, or qualifications.
3. Somewhat True: The job description is partially accurate. Some responsibilities, required skills, or qualifications
may be overstated or understated.
4. Mostly True: The job description is largely accurate, with minor discrepancies in the responsibilities, required
skills, or qualifications.
5. Completely True: The job description accurately represents the job title, responsibilities, required skills, and
qualifications without any exaggeration or understatement.
# Evaluation Steps:
1. Carefully read the entire job description, focusing on the job title, responsibilities, required skills, and
qualifications.
2. Evaluate the overall factuality of the job description based on the provided criteria.
3. Assign a factuality score ranging from 1 to 5, using the Evaluation Criteria as a guide.
# Required Skills:
{skills}
# Required Experience:
{experience}
# Job Description:
{job description}
# Evaluation Form (scores ONLY):
Figure 6: The prompt used for assessing the factuality in generated job descriptions. We use the same prompt,
changing job descriptions to resumes, for resumes as well.

Write a job description for a “{job title}” job which require only skill set of “{list of skills}” and only previous job
experience of “{list of experiences with augmented years for job description}” and a matching resume for a candidate with
the name of “{sampled first name}” and having only skill set of “{list of skills}” and only previous job experience of
“{list of experiences with augmented years for resume}”. Then generate exactly the same resume (keeping everything the same)
but excluding skill set of “{list of skills to be removed}” and “{the modification to last experience}”. Don’t include any
extra skills and experience. But generate extra details about provided skills and job experience. The job description should
only contain Job Title, Job Summary, Required Skills, and Responsibilities sections (only include few responsibilities).
Resumes should only contain Personal Information (containing the provided first name and a matching generated last name and
email), Education, Skills, and Experience sections. The generated output should exactly be according the following structure:
###### Job-description
## Job title
.....
## Job Summary
.....
## Required Skills
.....
## Required Experience
.....
## Responsibilities
.....
###### Resume 1
## Personal Information
.....
## Education
.....
## Skills
.....
## Experience
.....
###### Resume 2
## Personal Information
.....
## Education
.....
## Skills
.....
## Experience
.....
h output:
Figure 7: The prompt used for generating documents in RJDB generation pipeline.
